
[Focus 5]Using and interpreting 'official figures'Recognising misleading or corrupted data |
| There is a weakness when dealing with statistics that have been generated elsewhere and by other people. We do not necessarily know how reliable the data is, how it was collected or how much it has been 'manipulated'. It is essential that your sources are honest and reliable. 'Clever'
presentation can easily mask unpalatable facts.... |
It would be useful to familiarise yourself with the 'kinds of data', the presentation and the relative merits of different methods of presentation before continuing. Browse through some of the websites selected as they are representative examples of datasets that are in the public domain.
You will find that it is just as important to be able to interpret and judge the work of others as it is to have your own statistical work accepted as ethical and accurate.
Go to Sources of electronic information
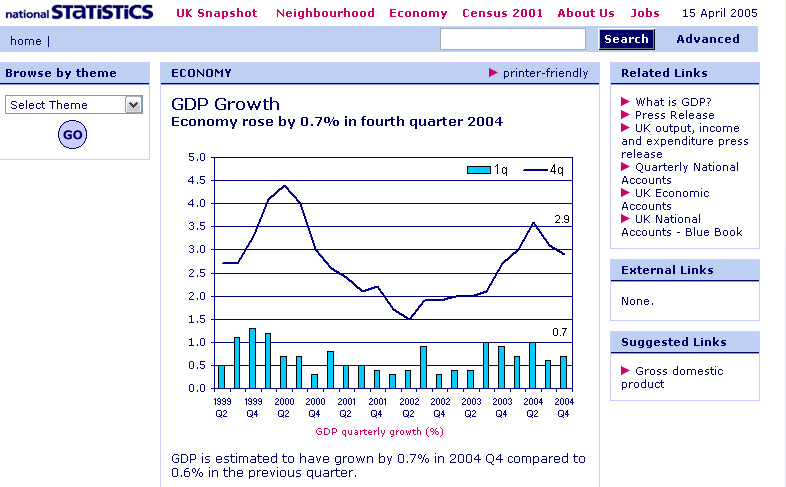
BUT...in the banner headline, there is no mention that the 4 quarter trend (see Focus 12) is falling quite steeply and has been for some months!.
Television advertising will often make bold claims such as "this yoghourt will reduce your cholesterol levels by up to half" ....half of what?....do they mean by 50% or do they mean half of eight is 4 and if so, what if your cholesterol level is already 4...will it now be reduced to 2! How should we interpret such claims and are we being deliberately misled?
As writers of such strap lines...do we have a moral duty to be absolutely honest?
How often today do we hear that some pressure group or opposition party wishes to take issue with 'official government statistics'. Political parties spend a lot of time trying to convince us that their opponents' fiscal calculations "just don't stack up". Certainly within Treasury circles, the National Health system and the education system, this is a daily occurrence.
Often statistics will confuse because units are omitted or not properly applied. We are all very gullible where numerical data is concerned and 'official figures' will frequently overawe us. Of course this can also lead to the opposite view; that of great cynicism, where we don't trust any statistics.
| Should
the motto be:"it must be true, I saw it in an official table" or "don't believe anything you read unless you wrote it yourself". |
Suppose a company (employing 5000 people) carried out a survey asking 100 staff members whether they had been abroad in the last 6 months.....
82 said they had.
This might be reported in a number of ways:
1) Simply as it is stated
2) "82% of people questioned have been abroad in the last six months" (no reference to how many were asked out of a possible 5000)
3) "82% of the company staff have been abroad in the last 6 months" (completely not true).
4) "82% of the population have been abroad in the last 6 months" (gross extrapolation....that would mean some 50 million people).
Or: "72% of motorists disapprove of the use of mobile phones when driving"
1) How large was the sample size? ....... is this in Poole, Dorset, the UK, Europe or the whole world?
2) Why only ask motorists?
3) How was the question phrased...what choices of answer were the respondents given?
4) Were the respondents referring to other people using mobile phones or were they including themselves in their disapproval?
We can see that gathering spurious data is very easy and can be presented in such a way as to suggest that it has been collected in a valid and meaningful way.
The
problem with gathering accurate data is that it is a expensive, painstaking
process and often
very time consuming.
Of
course there are methods of collecting data that can be analysed and interpolated;
e.g. regression (Focus 10).
It is always important that an adequate sample
size is used and that all the methods are clearly explained to the reader so that
his / her interpretations of the data are not to be misled.
Sampling error is not the same as sampling bias; the former refers to the fact that we always have to use samples (taken from a population) rather than using the whole population. Sampling error is ever present, it is introduced because individuals vary within their own population and chance variation plays a part also.
Sampling bias refers to the accidental (or deliberate) weaknesses of the chosen sampling method. The former is unavoidable, acceptable (and can be minimised) and is therefore legitimate, the latter is not.
Even when data has been collected in a carefully controlled manner it may be that certain values appear to be too large or too small (such values are called 'outliers'). Do we include them or do we leave them out? Mean values are notorious for being easily affected by just one or two rogue values in a data set.
Look at the following chart:
16 men in an advertising office were asked what their age was when they first got married:
| 24 |
23 |
27 |
24 |
| 26 |
19 |
22 |
26 |
| 23 |
25 |
23 |
24 |
| 19 |
24 |
27 |
39 |
The mean value is: 24.7 but if we leave out the last value (39) the mean age becomes 23.7.. a full year less!
We have noted previously that the mean is very sensitive to such 'outlier' values.
Even if we used a much larger sample size there is always the possibility that outliers will occur.
Any
good article, report or dissertation must be based upon representative samples
and this means that every source of bias has been minimised. In theory, the only
type of sample that can be tested statistically with impunity is the true random
sample. This is one picked completely by chance from
the total population
to which that sample belongs.
A further source of confusion can arise in official documents when the Mode or Median values are quoted and termed 'the average'. It may be that whichever of the three options demonstrates the writer's argument in the best light will be the one that will be used.
 Fact: "In
1935 the incidence of Polio (among children) in America was 0.17%"
Fact: "In
1935 the incidence of Polio (among children) in America was 0.17%"
In a vaccine trial involving 1177 children, (carried out by the vaccine manufacturer), 502 were vaccinated (42.65%) and 675 were monitored as controls. None of the vaccinated children developed the disease but neither were there any cases amongst the control group. The company concluded that the vaccine was effective!
But at that rate of current incidence (1.7 cases per thousand) only 2 cases would have been expected to have occurred anyway, regardless of any treatments! Obviously a much larger sample would be needed (at least x10) before any valid conclusions should have been drawn. If such trial results had been furnished with the level of significance, it would have immediately shown up the inadequacy of the method.
Remember also that the spread of the dataset may give valuable information and help the reader because the spread will indicate whether the results are bunched around the mean or conversely much dispersed and away from the mean.
It
is important to ensure that as much of the raw data as possible is presented to
the reader in
an easily digested fashion.
 Consider the following newspaper statement...
Consider the following newspaper statement...| "There
are 4 times more accidents on the M1 between 6pm and 7pm than there are between 6am and 7am". |
This
may well be true but the statement is misleading because
it does not take into account that there is far more traffic using the road in
the evening rush hour than in the very early morning.
There is nothing here
to prove that you, as an individual driver are at any more risk in the
evening
than in the morning.
In the above case it would have been more meaningful to compare traffic density (cars / hour) with accidents / '000 traffic movements. By taking observations at different times of the day it would be possible to comment authoritatively on accidents related to time of day if that was the intention of the exercise. A Pearson's correlation test would then be appropriate (Focus 10a).
When attempting to make inferences from your results, be very sure that your conclusions are supported by the data and the analysis that you have done. Your statements and conclusions have to be robust and capable of scrutiny by others.
Care
must be taken when using percentages especially if you are trying to indicate
the magnitude
of an increase or decrease in a variable. Look at this newspaper
headline.....
"Travel Trade panic:Spanish holiday bookings crash by six and a half per cent" |
Even if we ignore the hyperbole, this sounds quite serious but let us look at the figures....
| Holidays ('00,000) | 2003 | 2004 |
2005 |
| to Spain>> | 110 | 140 |
131 |
| to Greece>> | 70 | 80 |
94 |
Totals | 180 | 220 | 225 |
| % change overall | | +22.2 |
+2.3 |
220÷180 = 22.2% increase and 225÷220 = 2.3% increase so in fact, there was a nett 25% increase in trade over two years!! The reporter chose to use just two of the figures made available to him (131÷140 = 93.6%...a 6.4 % decrease) in order to create a 'story'.
This 'selective use' of data is tempting because it often illustrates what the writer wants to promote but data that does not fit your theory or thesis can be just as valuable, especially in research situations.
If in doubt, it is better to simply report the descriptive statistics and dispense with %'s unless you are quite sure that they are unambiguous.
The main area where percentages are useful are where you have unequal sized samples (that are quite large) and you wish to make simple, generalised comparisons.....
 E.g. " 14% of UK teenagers are overweight but 26% of American teenagers are
overweight".
E.g. " 14% of UK teenagers are overweight but 26% of American teenagers are
overweight".
Q. Can you list the potential pitfalls contained in the above statement?
We discuss a better way of making these comparisons in a less ambiguous way in Focus 7:Index Numbers.
When carrying out market research, remember that it is individuals that you are dealing with and not simply numbers. Be aware that an over-emphasis on %'s and 'Incidence' may not be welcomed by your 'sample'.For example, imagine you are researching for an article about credit card fraud. If you discovered that only 1 person in 15,000 is a victim of credit card fraud; it would be perfectly correct to say that the incidence of this crime in the 'population' was 0.000067%. However, if you were interviewing that one person; the statistic could cause distress. To that person; the incidence feels like 100%. |
An association between two factors is not proof that one has caused the other.
We cannot say "if B correlates with A, then A has caused B".
 For example, in third world countries, there is a close correlation between the
incidence of disease and the lack of a clean water supply. It is tempting to say
therefore that dirty water causes disease. This is incorrect, because whilst
there is a strong connection, it is the microorganisms in the water that
cause the diseases not the water itself. Victorian scientists and engineers struggled
with this notion for decades.
For example, in third world countries, there is a close correlation between the
incidence of disease and the lack of a clean water supply. It is tempting to say
therefore that dirty water causes disease. This is incorrect, because whilst
there is a strong connection, it is the microorganisms in the water that
cause the diseases not the water itself. Victorian scientists and engineers struggled
with this notion for decades.
Here is another example....the suicide rate in Britain reaches a peak each year around Christmas. So we can say that there is a positive correlation here. There is some sort of connection but that is all. We cannot conclude that "Christmas causes suicides".
Correlation and regression tests should always include confidence limits before any conclusions are drawn about the nature of the relationship between the variables under scrutiny.
Pictograms
are commonly used in newspapers, magazines and government leaflets.
They
are intended to display numerical information in a non-mathematical way to a non-specialist
audience. They are supposed to be self-explanatory and are therefore often accompanied
by little or
no explanatory text.....
 |
But what information do the images above really convey?
|
Here is the 'same' information offered as a pie chart....
This is slightly less misleading but there are no units displayed and so the proportions are meaningless. Avoid graphics that confuse. They are frequently used in populist magazines and newspapers because they do add dramatic effect to an idea. However, they are generally imprecise as a technique for conveying truthful information and are easily misinterpreted by the reader.
For this reason, they are best avoided in academic, serious or commercial writings.
By manipulating the scales on either axis of a graph a very different image can be created. With Excel and SPSS graphics it is very easy to change the scales on one or both of the axes to 'enhance' the separation of points. The same problem arises with histograms and bar charts. Where differentials are to be displayed it is important that the absolute values of each class are displayed in full...
 Consider the following imaginary case.
Consider the following imaginary case.
A
fertiliser manufacturer has recently developed a new growth-promoting product
for potato growers called 'Maxispud' but there is
disagreement between the R & D and the advertising
department as to how
they should promote the product ....
All hinges upon what rate of use to recommend to the growers. Who will win....?
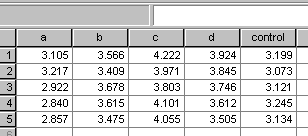
Five large-scale commercial trials had been undertaken that involved 4 levels of treatment (5, 10, 15, & 20 l/ha in 1000l of water /ha) and a control (no treatment).
Here are the results (tonnes / hectare) from the 5 trials:
therefore,
mean yield values are:
2.99 | 3.54 | 4.03 | 3.73 | 3.15 |
and here is the 'honest' bar chart that reflects those results...
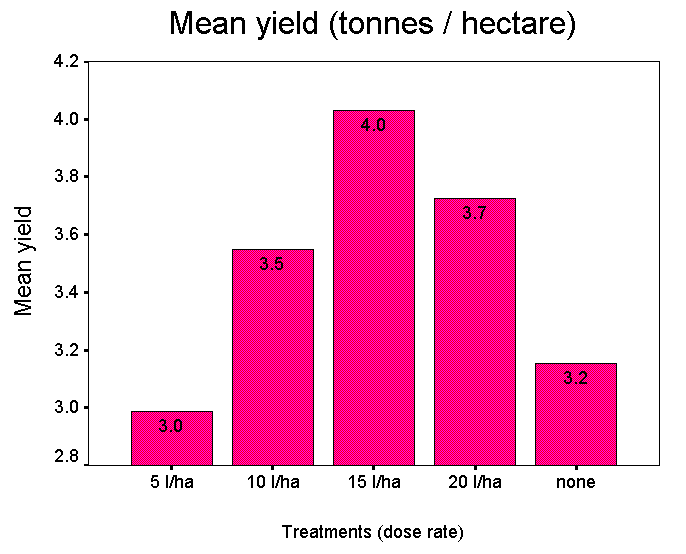
Note that the lowest dose rate actually depressed yields when compared with the control plots. This may be a fact that the manufacturer will not wish farmers to know.
So, if we delete all but the 'best' column and 'resize' the graph, we can generate quite a different perspective on these results....
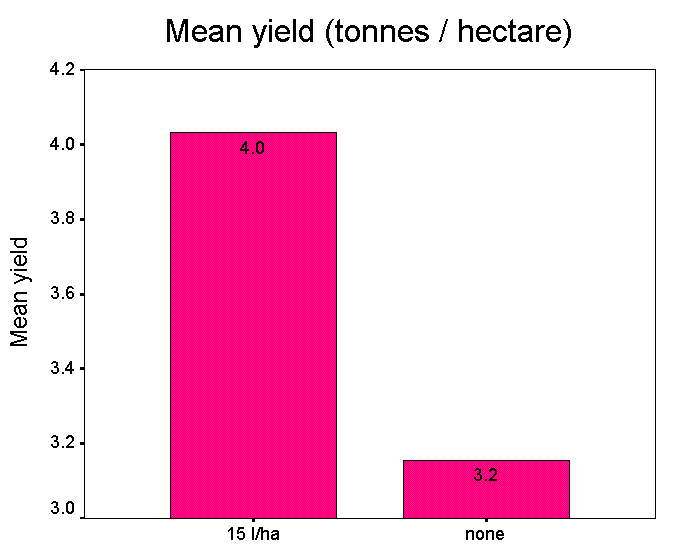
| "
Maxispud can help you to increase yields by more than 37%" |
If we look back at the original data set you will see that in order to use the figure of 37%, the lowest yield from the controls has been compared to the highest yield obtained from the 15 l/ha treatment...
4.222 ÷ 3.073 =1.3739. i.e. 37.4%
The mean yield improvement at this dose rate would only be 4.03 ÷ 3.15 = 27.9%.
The advertising department argue that 20 l/ha would be preferable because the company would sell more material that way but the mean yield improvement would only be (see table above) 3.73 ÷ 3.15 = 18.4%
Should the grower benefit most or should the manufacturer?
Let us consider the 'quality' and 'honesty' of this work....
| *** No reference has been made to the cost of treatment. If the material is expensive then the extra yield may not be sufficient to cover the cost of materials and application. *** No reference has been made to other factors that might have affected yields such as soil types and weather conditions during the growing period. *** No secondary control was implemented whereby plain water was sprayed on the crop at 1000 l/ha. It may be that it was the water that contributed most to the increase in yield!. *** No reference has been made to crop residues or potential taint on the crop. *** No reference has been made to the fact that the yield actually dropped when more than 15 l/ha were applied to the crop. The saying; "let the buyer beware" may still apply but deliberately giving out misleading information is unacceptable. |
In other words, whilst the product may well be a useful and practical one, the way that the the trials were designed and the statistics generated, can both be manipulated to show something in a false but favourable light.
The reverse might also apply, a competitor company may carry out trials against their product and then issue the 'worst case' results to the farmers. Result: misinformation and confusion.
These dubious methods are an ever-present danger.
This may seem obvious but it is not uncommon to receive datasets where, for example, the average age of soldiers in the British Army is 11!! or where the national average wage is £200,000 per year!! If the dataset is in electronic form and the errors are not picked up immediately, the string of calculations will still run but the results will be worthless. Both time and effort have been wasted. It is always useful to carry out cross-checks and produce charts wherever possible during the analytical phase to ensure that mathematical or typological errors do not creep in.
In this simplified example, comparing gross salaries with age groups; just one digit (a '1' instead of a '3') has made an interesting chart worthless.
![]()
![]()
In some
cases these problems arise through ignorance or by accident rather than design
but it is important that in your work, you endeavour to ensure that your results
are presented in an honest
and forthright way and that any conclusions you
make can be substantiated by your test methods
and results.
Your work must stand up to rigorous peer review. |
Never be tempted to fabricate data or to present what you would have liked to happen, you will be found out! You have an implied duty to be honest.
Furthermore, it is very wasteful to collect and collate your data properly and then fail to extract the hidden (but valid) information that it contains.
| Finally....never discard your original data; even if it is just pencil ticks in a notebook. You never know when you (or others) might need to go back to check on something vital that was scribbled down right at the beginning of the project. |
![]()